
Rob AI Project
Almost ten years ago my university roommates discovered a very interesting and challenging programming game: RoboZZle. We spent weeks writing little programs for a robot, that would navigate a labyrinth to collect rewards. Now as a small step towards self-programming AI we are launching a project to beat RoboZZle programming game with machine learning.
Introduction
About the game
There are thousands of community-made puzzles. Puzzles are 16x12 fields with cells colored red, green, blue, or black (impassable). There’s also a robot, and a set of one or more rewards to collect.
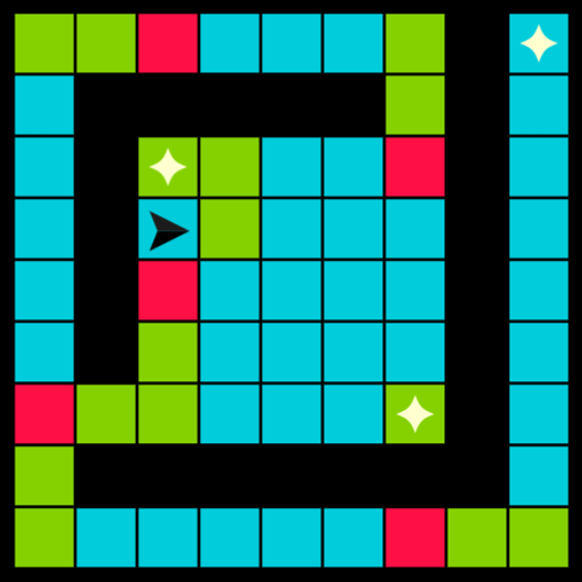
The task is to write a program for the robot to collect all rewards.
A program consists of 1-5 functions of fixed length (specified by a puzzle). Commands are limited to movement, turns, calling other functions (with a typical stack semantics), and sometimes cell repainting. An example instruction set:

Colored instructions are conditional - they only execute if the robot is on a cell with corresponding color.
You can see an example solution in action:
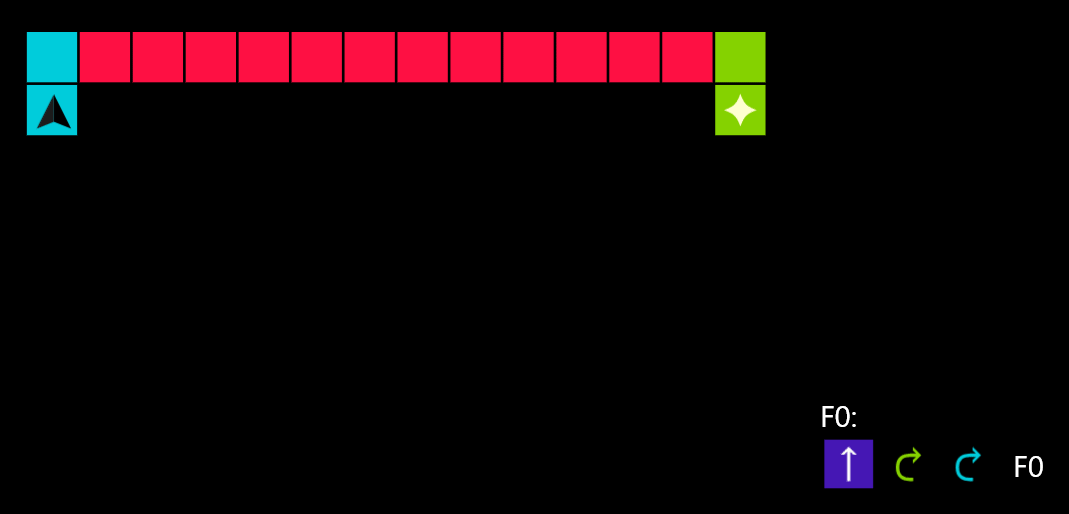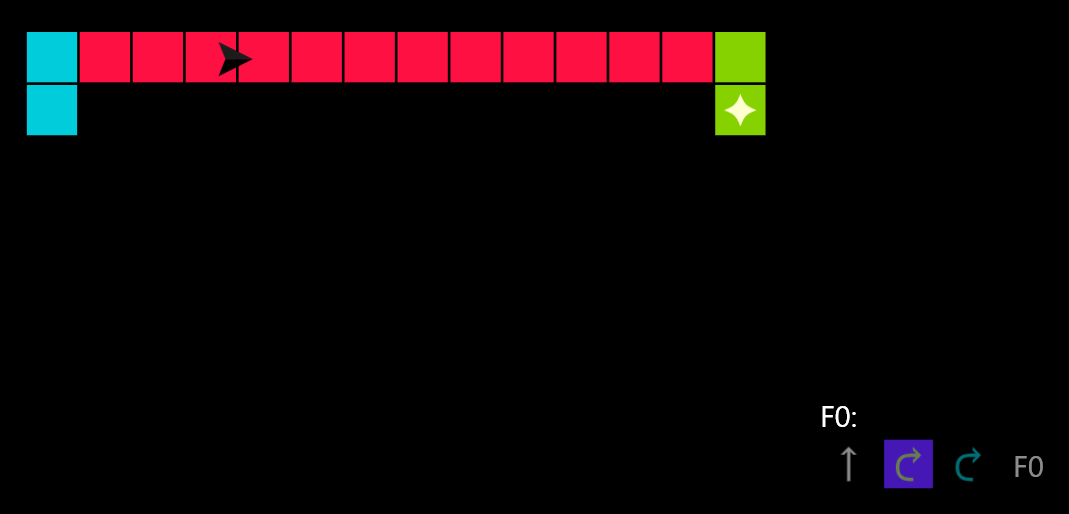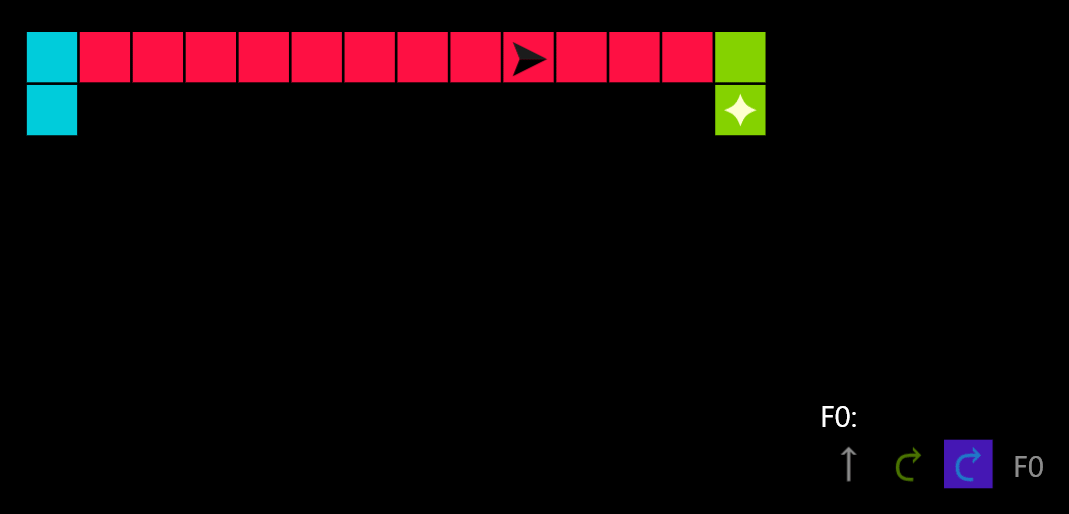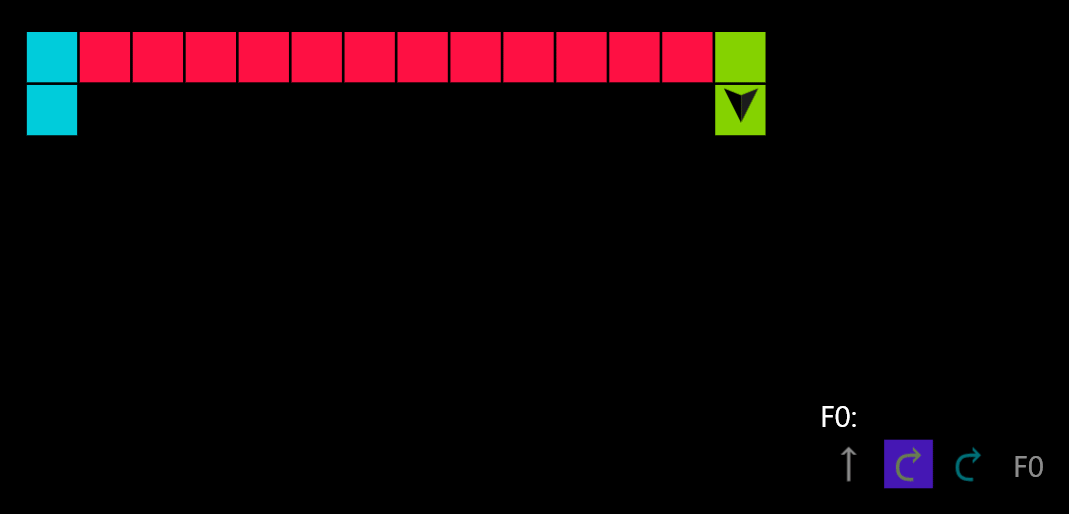
Getting there
Data collection
Having the right training data is the most important part of any machine learning process. While we could have tried to make computer sort of teach itself, it is usually much easier to give it examples to learn from.
So we turned to the community.
The data we want here is a step-by-step list of operations an actual human does. E.g.
- start with an empty program
- replace command 1 with “Go Forward”
- replace command 2 with “Call F0”
- run the program and watch the robot fail miserably
- replace command 2 with “Turn Left on Green”
- rerun
- etc
If we collect enough of these sequences, we can use a supervised learning algorithm to predict the next action a human would make in a given state to solve the puzzle.
Right now we collect this data (with user consent) when folks play our Android game port or its Windows Store brother (PC, Xbox, Mobile, and Hololens).
Predicting the next move
With the abovementioned data, guessing the next human move is just a classification task. Input data is a picture of the game field, current program, and also a number of steps the robot has made since start (if it is currently running). Output is what to do next: edit the puzzle (also, how to?) or start or stop the robot.
It would be inefficient to feed the training algorithm with actual screenshots from the game, as they would have relatively high resolution. Instead, in our current approach we encode game state and current program as a small (51x31) grayscale image, where colors are encoded with brightness.
For example, this is how a solving session for The Chambers puzzle looks like to our initial model:
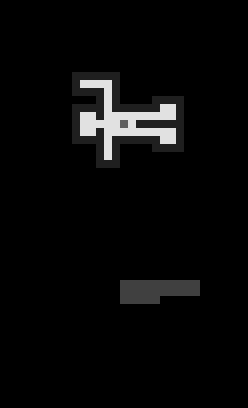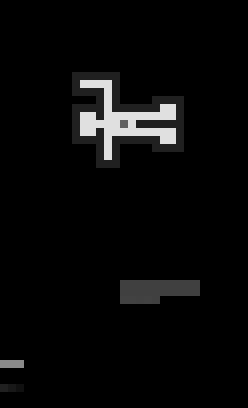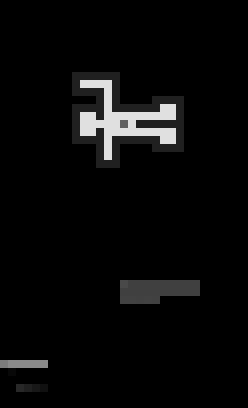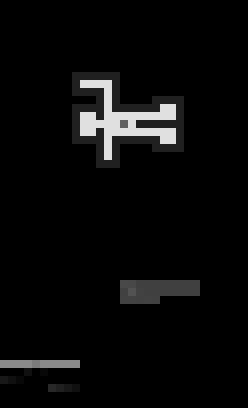
The man figure is the actual field, grey area below him is the user program, and the line, that grows from the left side encodes the editing history.
You might notice how “man” rotates and the program shifts. Its our attempt to aid neural network to match current position and rotation with the next command(s) robot is about to execute. Which we will talk about in later posts.
Going forward
We have just started building a convolutional neural network model to fit this data.
Why convolution? Because important puzzle elements are typical for 2D images: edges and corners, color-coded turns, repeatable 2D patterns. Usually, LSTMs are used for generating sequences (like a program editing action sequence), however I believe CNNs just might work better if augmented with some historical information.
In the next post I will share more details about how we preprocess and generate training data from user telemetry.
Meanwhile, you can join our project by playing the game on Android or Windows.
Stay tuned for more!
Sign up for updates over email or to leave a comment. You can also subscribe to RSS with the link in the footer.